About 8 months ago, I decided to build a masterless, clustered redis clone with a more robust persistence and clustering strategy called kickboxer. One of the main challenges implementing a distributed redis clone is that almost all operations require doing a read before a write. Additionally, since most of the operations require a type check, operations would have to be executed in the same order on each node.
While guaranteeing the order of operations in a single threaded server is no problem, things get a lot more complicated when dealing with distributed systems. Machines go down, messages sent between machines are delayed, lost, and reordered, network connections fail, and it's generally a bad environment for doing anything that needs a guaranteed order.
To guarantee the ordering of queries for kickboxer, I needed to use a consensus protocol, like paxos. Paxos works around these problems, and guarantees the ordering of operations across unreliable machines. After spending a lot of time researching how each of the various paxos variations worked, I settled on egalitarian paxos. In this post, I'll explain the basics of how most variations work, how egalitarian paxos works, and why I decided to use egalitarian paxos.
Paxos
Paxos is a method of achieving consensus in a distributed system. Applied to distributed databases, it means guaranteeing that the same queries will be executed in the same order, on every machine.
With most flavors of Paxos, this is acheived by numbering queries as they come in. A client sends a query to a machine, which becomes the proposer for this query. The proposer assigns a proposal number to the query that's higher than any it's seen so far.
The proposer then asks the other nodes to promise to not accept any queries with a proposal number that is less than this one. The proposer waits for responses from a quorum of nodes. If this is the highest proposal number the nodes have seen, they will respond with the promise. Otherwise, they reject the request, and return the highest proposal number they've seen. This ends the round. The proposer can either abort the query, or try again with a higher proposal number.
Assuming none of the nodes rejected the proposal, the proposer sends an accept request to the nodes. If the nodes have still not seen a higher proposal number, they will accept the request. Once a quorum of nodes reply with an accepted response (and none have rejected the request). The proposal is considered accepted, and can now be executed.
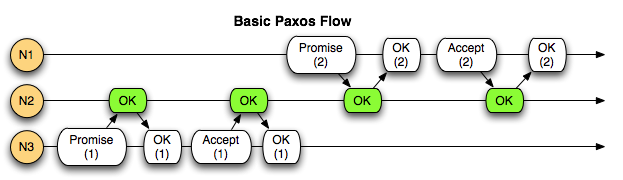
While this guarantees the ordering of queries, in situations where the cluster is receiving queries faster than it can get them accepted, newer queries with higher proposal numbers will prevent older queries from being accepted, which then are then prevented from being accepted by even newer queries, leading to a condition called live lock. The cluster is up and working properly, but nothing is getting done, because requests keep getting invalidated by newer ones before they can complete.
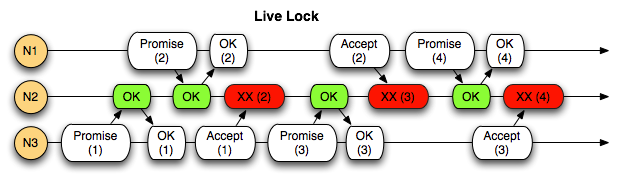
This problem is often solved by designating a master node. A master is elected by the other nodes, and is the only node that will execute queries while it's designated the master. When the master node's master lease expires, or the machine fails, another node is elected master and things proceed as usual. The problem with having a master node is that all queries have to be routed through a single node, creating a bottleneck. The Mencius paxos variant does work around this problem by constantly rotating the master status between nodes.
Egalitarian Paxos
Egalitarian paxos takes a different approach on how it provides query ordering guarantees. Wheras classic paxos orders proposals by using incrementing proposal numbers as a gatekeeper for accepting proposals, egalitarian paxos accepts any new proposal, and determines the ordering of the instances at the time of execution.
It achieves this by building a directed graph of proposals. As new proposals come in, they gain dependencies (edges to) previous proposals. If two proposals arrive at the same time, they will gain dependencies on each other, but will still be committed. Once the nodes agree on which dependencies a proposal has, the proposal will be committed, and once committed, it can be executed.
Interfering Proposals
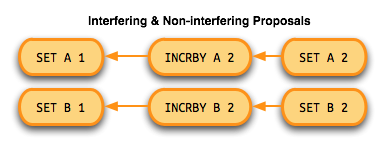
When adding dependencies to proposals, only interfering proposals need to be added as dependencies. For instance,
SET A 1 and SET B 1 touch different keys, so they don't interfere with each other. Since they don't interfere
with each other, there's no need to enforce an order on the execution of them, so the proposals don't gain dependencies
on each other. On the other hand, since the commands SET A 1, INCRBY A 1, SET A A all mutate the same key, they do
interfere with each other. Those queries, and any new query that affects the key A will gain dependencies on the
previous proposals that touch A.
Preaccept Phase
When a client sends a query to a machine, that machine becomes the leader for the proposal. Before communicating with any of the other nodes, the leader needs to assign dependencies. It finds previous proposals which interfere with the new proposal, and assign them to the new proposal as dependencies.
The leader then sends this proposal, with it's dependencies, to the other nodes, and asks them to pre-accept the proposal as well. The other nodes will then assign dependencies to the proposal based on their view of interfering proposals, and reply to the leader.
Once the leader receives a quorum of replies, it will check the dependencies returned by the other nodes. If the dependencies from the other nodes all agree with each other and the leader, the leader will commit the proposal locally and asynchronously notify the other nodes that the proposal has been committed. If the nodes do not agree on the dependencies, the leader moves to the accept phase.
Accept Phase
When the leader receives different dependency sets from the nodes for a given proposal, it means there are proposals in flight that one or more nodes haven't seen yet. When this happens, it combines all the dependencies from all the pre-accept responses and sends them to the nodes in an accept request.
The accept request tells the nodes to accept the updated set of dependencies as the dependencies for the proposal. Once a quorum of nodes have responded to the accept request, the leader will commit the proposal locally and asynchronously notify the other nodes that the proposal has been committed.
Execution
As I mentioned earlier, the execution phase is where the ordering of proposals is determined. The stages leading up to the commit were building a directed graph. The preaccept and accept phases, and the quorum response requirement for each stage guarantees that a given proposal will have dependencies to any interfering proposal that came before it.
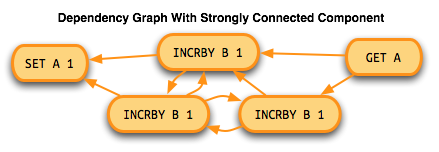
To determine the execution order, strongly connected graph components (sub graphs with cycles) need to be identified and sorted in reverse topological order. The strongly connected components then need to be sorted using a tiebreaker value. The Carnegie Mellon paper uses an integer that's assigned when calculating dependencies. Since kickboxer uses uuid1s for proposal ids, it compares them for the tie breaker. Once the execution ordering is determined, the proposals are executed in order. All of a proposals dependencies (and the proposals they depend on) must be committed before an instance can be executed.
Trade Offs
As with anything, there are trade offs involved in selecting one approach over another. Below are some of the advantages and disadvantages of using egalitarian paxos over other variations. I haven't implemented other variations of paxos, so there may be some points that I'm missing here.
Masterless
The main thing that attracted me to egalitarian paxos was that it was compatible with the idea of a masterless system, since the protocol has no concept of a master node. Not having to deal with master election, and how to recover from a failure of the master node was a big plus. With egalitarian paxos, as it's name implies, all nodes are equal, and can execute queries without getting in the way of other queries.
Interfering Proposals
Since the ordering of proposals depends on interfering proposals, by being intelligent about how you determine which proposals interfere with each other, you can make 2 optimizations. Reducing the number of interfering proposals is important, because the fewer interfering proposals there are in flight, the lower the probability that you'll need to run an accept phase, saving a network round trip.
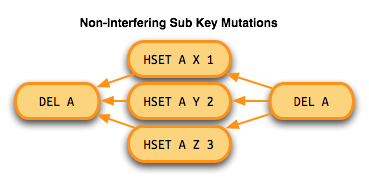
First, with nested data structures, like redis's hash structure, or Cassandra's key/column/value structure, you can update single
components without interfering with others. For instance, HSET A X 1 does not interfere with HSET A Y 1, although DEL A
interferes with both.
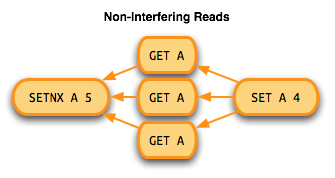
Second, reads don't interfere with other reads. Since the ordering of reading the same value multiple times doesn't matter, reads only need to gain dependencies on the most recent writes. Subsequent writes will then need to gain dependencies on every read that has occured since the last write
Best Case Commit Time
In cases where there are no in flight proposals which some nodes are not yet aware of, the leader can respond to the client after a single network round trip to the other nodes. This is because the response to the pre-accept request will all have identical dependencies (so the accept phase can be skipped), and because non leader nodes can be notified of commits asynchronously. In many use cases, this will be the usual behavior as long as there isn't a lot of activity around a few keys.
Increased Bookkeeping Complexity
Since determining execution ordering is deferred until execution time, doing the bookkeeping required for correct failure recovery seems to be a lot more intense than it would be with other paxos variants. If a node goes down, and then rejoins the cluster some time later, it will need to discover every proposal that has been committed in it's absence. This makes how and when to garbage collect old proposals a little tricky, and I haven't come to a conclusion on the best way to implement this yet in kickboxer.
I hope this has offered some insight into how Paxos works and why it's so useful in a distributed system. If you'd like to read more, check out the original Carnegie Mellon paper (pdf) as well as the kickboxer paxos source. The kickboxer paxos implementation is working, but not completed. As things progress, I'll be covering approaches for ordering proposals that touch multiple keys living on different shards, challenges implementing egalitarian paxos, and the kickboxer storage engine.